I don't think Matillion implemented paging in that part of the API.. so during processing it tries to hold up to an entire year's worth of task history in memory. That's what can cause the OutOfMemoryError: Java heap errors.
According to the docs you can filter by date range... http://<InstanceAddress>/rest/v1/group/name/<groupName>/project/name/<projectName>/task/filter/by/start/range/date/<startDate>/time/<startTime>/to/date/<endDate>/time/<endTime>
SO you may be able to loop for example month by month and fetch a smaller amount of data at one time.
I have experienced the same issue with the API Exctract Component and the Task History API. You have to add a filter to reduce the number of task history entries. From my experience, it is not possbile to query more than week of task history data. All above causes the OOM error. Of course this depends highly on the number of jobs/tasks that you run per week.
I have dismissed my plans to use the API and I now query the local Postgres Database directly. This is much faster for larger amount of data and does not cause memory issues. I know that this is not the officially supported way to access the data but it works very well for us. Perhaps this is an option for you?
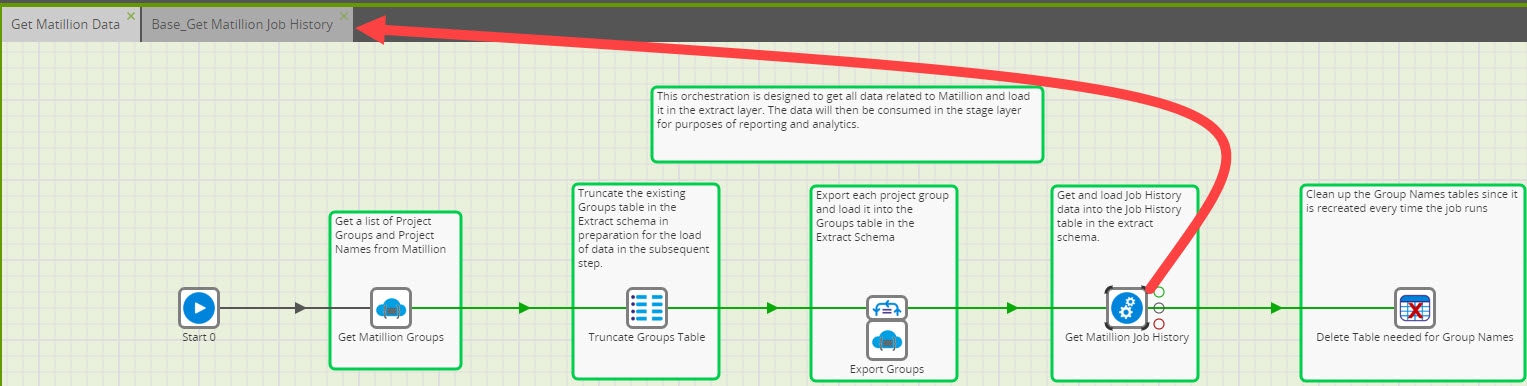
There are some issues with API Extract which I suspect will get fixed and also made better. Feature wise, API Query profiles can do all the same things as API Extract but the difference is that you have to write the RSD. We are doing exactly what you are attempting to do with Task History using the API Query. We extract the history every night and load it into Snowflake.
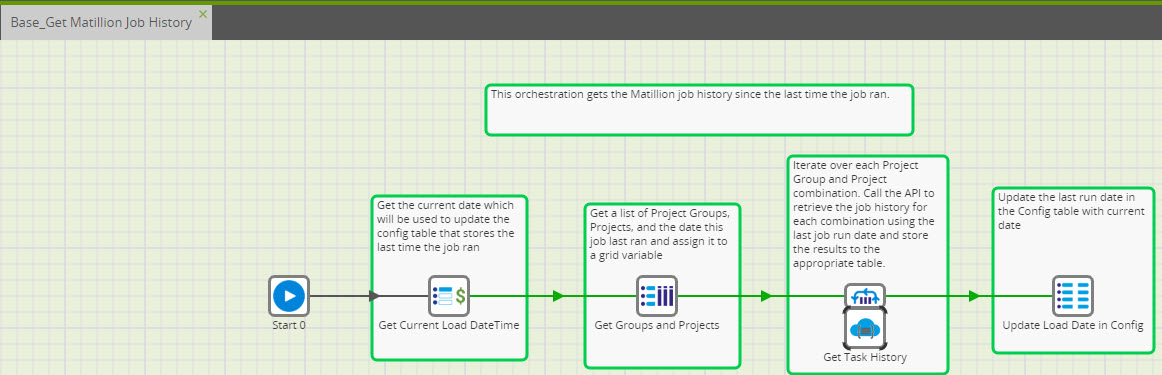
We are doing this extract a little different than what you are attempting to do. The first load needs to be loaded in batches which is easy enough using start and end dates and times. Then we load incrementally every night based on the last load date and time. Keep in mind there is an end to Task History. Meaning, Matillion only keeps so much history before it starts falling off the end. This is another reason why our job runs daily. We are ensured that we are getting all of history since we are loading every night.
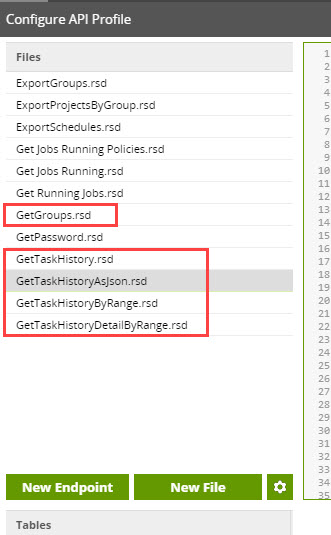
I have attached our API Query Profile that has all our Matillion API defined methods or calls that we use. The specific ones that would be of interest to you would be these:
If you plan to load the JSON directly from the database you should plan on it breaking at some point. There is no guarantee that the data will be the same or that Matillion won't change the schema of the database from version to version. This is why the API method is safer. If they change the schema of the database or change the data the API's will follow those changes and just keep working. I hope this helps!
Could you elaborate more on how you connect directly to the postgres database? I too am not satisfied with their API method for extracting this information and would rather just get it directly from their DB tables.