Hi @JFS,
Lots going on there!
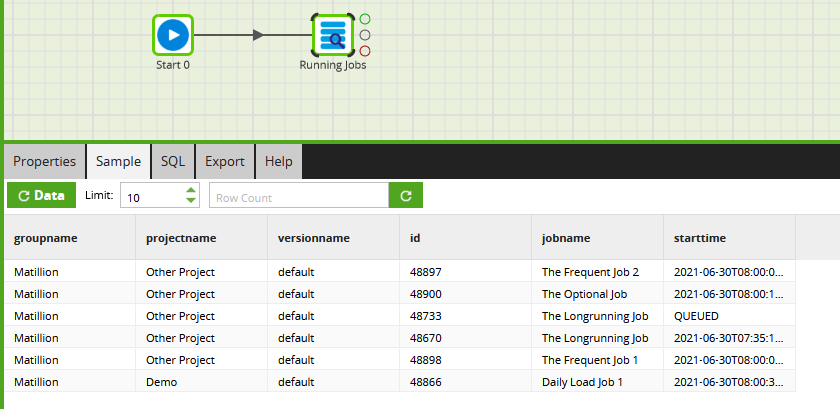
First of all, your curl command looks correct to me. I copied and pasted it, changed the names of the Project, Environment etc and ran it from an SSH session in my own Matillion instance. First with an Orchestration Job, and then afterwards with a Transformation Job:
The first one worked, and it returned the task history ID of the newly running job.
But trying to run a Transformation Job in that way is not permitted. You are only allowed to launch an Orchestration Job via the API. I think we may have changed the error message for that situation over time, so you might see slightly different. The above screenshot is from Matillion ETL 1.54.
But in any case I’m not 100% certain why that restriction exists. Transformation Jobs are top-level objects, same as Orchestration Jobs, so it might be worthwhile adding that request to our Ideas Portal if it’s a big use case for you. (Same applies to Shared Jobs).
There’s no need to refer to folder structures or paths with the API. All job names are forced unique so you can’t have the same named job in two places in the folder structure.
Regarding the ‘failed to retrieve’ error, I believe that’s just background noise in the logfile. On most (all?) instances, if you run:
sudo grep “failed to retrieve the” /var/log/tomcat*/catalina.out
… it returns a lot of lines. I don’t know why those messages appear, but it does not seem to cause any problems.
The last thing is the ‘Connection refused’ error. Out of the box, Matillion listens on ports 8080 and 8443. Those get redirected to the standard HTTP/S ports by an iptables redirect so it looks to non-local users like it’s using the standard ports. You can see that by running a sudo iptables -L -n -t nat command from an SSH session.
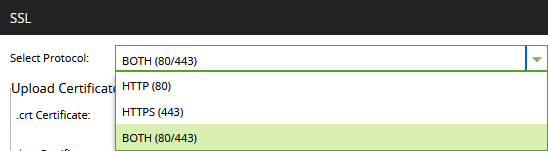
But it is possible to switch the listeners around from their default positions, from the Admin / SSL menu.
So if you're trying port 8080 and getting a connection refused error, my guesses would be:
- You're not running that curl command from on the Matillion instance (use port 80 instead if you're not on the instance)
- You have switched off the HTTP listener
- The iptables redirects are missing
Hope that makes sense and is helpful!
Ian